作者: songtianyi create@2020-11-08
计算机技术非常庞杂,而且仍在快速更新,面对越来越多的新技术,我们似乎跟不上了。如何面对新技术,如果面对换工作时的技术迁移,是必须要考虑的。 优秀的程序员不会被技术迭代淘汰掉,也不惧怕切入新的技术领域。掌握一些核心的概念,可迁移的能力,是我们从容应对的底气。之后要介绍的内容,正是基于此而产生的,我个人认为比较重要的一些核心概念。这些概念虽然简单,但需要我们时常放在心上。
除了讲述基本概念,每个概念会附带一些技术名词,方便进一步学习。
协议,或者说约定,是我们构建系统的基础,我们制定标准,在标准的指导下通力合作,构建出一个个庞杂的系统。比如网络协议 tcp/ip,编码标准,编程语言,甚至我们平时说的普通话,都可以算作是协议。协议本身是很简单的,都是规定死的东西,重要的是协议为什么是这样设计的, 所以它的发展历程很重要。 我们在学 tcp/ip 的时候,如果一开始就扎进协议的细节里,会学的很痛苦,协议本身是很枯燥的,而且庞杂,好比我们学英语的时候去死背英语单词。正确的学习方式是,从简单的协议开始,理解协议本身,建立“每一个设计细节背后,都有一个精妙的设计初衷”这种观念,比如 tcp/ip 协议栈的层级结构,它在一开始就是这样的嘛,这样一个复杂的东西,是怎么一步步变成现在这个样子的,然后再一点点地去了解协议细节,以及背后的设计初衷。精密的事物,都有精妙的设计哲学在里面,重要的是,我们能感知这种哲学,感受设计者的思想,这才是最有意思的事情。
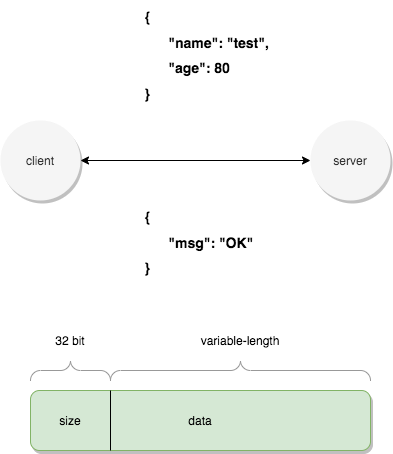
这里以入门级别的应用层通信协议设计为例。如下图,client 和 server 之间进行 tcp 通信,我们需要设计一个数据封装的协议,用固定的 32 bit 保存传递的内容的大小,之后接上要传递的内容,这样通信的双方能够正确地解码到传递的数据。实际上整个 tcp/ip 协议栈都是类似的实现方式,差别是:
关联技术:
编码与解码无处不在,在我的概念里,编码/解码是协议的实现,比如 utf-8 的编解码实现了 utf-8 这个标准。 编解码处理的是数据,而且一般成对出现,是可逆的,比如软件工程里的逆向工程;有些是不可逆的,比如有损压缩,你需要借助一些插值算法,才能把数据补回去,补回去的数据也并非原数据;再比如 hash,只有编码过程,没有解码过程。
之前面试的时候,有面试者说 SHA1 hash 是加密算法,虽然加密算法也是 encoding 的过程,但区别是,加密必然伴随着解密,即 decoding,所以 hash 只能算编码算法。这里引用一段英文的解释 [1],因为大部分中文教程里,都有 md5 是加密算法 这样的错误描述,导致很多人对此深信不疑。
By definition, a hash function is not encryption.
> Encryption is the process of encoding messages (or information) in such a way that eavesdroppers cannot read it, but that authorized parties can.
and
> Hash function is an algorithm that takes an arbitrary block of data and returns a fixed-size bit string, the cryptographic hash value, such that any change to the data will (with very high probability) change the hash value.
Encryption provides confidentiality while hash functions provide integrity.
Hash functions are used alongside encryption for their integrity capabilities.
我们在阅读代码或者 debug 代码的时候,多去寻找编解码的函数,如此,数据的边界、变化过程会比较清晰,便于我们快速定位出错的位置。 举个乱码的例子,很多人都遇到过乱码,有些情况比较简单,有些则看起来复杂。比如,同样的代码,在虚拟机上的输出是乱码,在本地 PC 上的输出却是正常的。如果我们只关注到代码是一样的,你会觉得这问题出的很是莫名其妙对不对,但如果你注意到,我们从程序里输出到 terminal 的内容,是会被 terminal 解码的,这时你应该会想到,是不是本地 terminal 设置的编码和远程虚拟机设置的编码不一致导致了这种差异。
关联技术:
二进制是我们在计算机人门时最先接触到的概念,虽然我们熟知二进制是信息最基础的表现形式,但我们并不一定时常能以这样的认知去看待事物。
以编程语言里的类型来举例,在我们的认知里,类型通常是不能随意转换的,你会遇到各种编译错误,但实际上是可以的。所谓类型,只是编译器用来约束变量边界的规范,任何类型,其本质都是二进制,我们可以用 int32 来存储 1 到 4 个 char ,也可以用一个 double 来存储 1 到 2 个 int32 , 还可以用 short 来存储 float 以降低 float 的精度,从而达到降低存储空间的目的等等。二进制级别的运算是很有意思的,让我们可以借助一些手段,在性能和存储空间方面做更深入的优化,也可以做一些精妙的 hack,但并不是所有语言都提供这种自由。
// c++
// 32bit float 降精度,用 16bit short 存,节省存储空间
void FPC::__32To16(const float x, unsigned short &res)
{
// little endian
assert(GABS(x) < 1.0f);
int nTmp = static_cast<int>(x*32768);
nTmp += 32768;
res = nTmp & 65535;
}
关联技术:
i/o 无处不在,但我们不一定会特别注意到它。比如磁盘 io,键盘(input)+显示器(output),网络 io 等。io 一般发生在软件与软件或者软件与硬件的边界处,对我们理解软件/系统架构至关重要。io 能够让我们比较容易地找到函数的边界,业务模块的边界,我们可以统称为逻辑的边界。
关联技术
"一切能用硬件实现的东西,都可以用软件来模拟“。这是一位学长教给我的至今印象很深的一句话。就像摩尔定律一样,这句话相当于一种论断,预言,它能带给你信心,也会促使你去寻找反例。我们可以用软件构建出一个和现实世界一模一样的虚拟世界: 仿真系统,虚拟化,自动化系统等等。
除了使用软件模拟现实世界这方面,模拟的概念也时常出现在使用软件模拟软件方面。比如,模拟浏览器访问网站,模拟软件系统中的某个组件,用来测试系统中的其他组件或者伪装身份等等。
人也可以被看作是硬件,只是人这种精密硬件,我们尚未完全掌握。
关联技术:
程序设计 = 数据结构 + 算法, 在 C 语言的第一堂课里,老师应该会给你们讲这个公式,它们的重要性不言而喻。数据结构用来组织数据,栈、队列、数组、链表、图、树,等等,我们需要掌握很多种数据结构,并关注它们的使用场景。算法和数据结构是相辅相成的,合在一起构成解决问题的方案,也可以认为是解耦的,同一个算法可以使用不同的数据结构来实现。
从我个人理解的角度以及实用的角度讲,数据结构要比算法重要的多,首先数据结构是我们解决问题的第一步,即,如何表达数据。表达数据不是单纯地存取它,而是发掘数据的内在规律,以一种较贴切的数据结构去表达数据的特性,如果我们很好地完成第一步,那么接下来就能比较容易地去套用成熟的算法了。
对于算法,学习应用是一方面,但更多地应该是理解其思想,比如二分,动态规划, 贪心等等。
当然,数据结构和算法是一个比较大的体系,这里仅仅只是做了入门级的介绍,确实单薄。对于本文来说,数据结构和算法是作为一个基本的原子性概念而存在,是属于整个原子概念体系里的一员,但也是在我们后续的学习成长过程中,需要重点拓展的内容。
关联技术:
我们熟知的操作系统都属于分时操作系统,这种分时机制可以让多个进程"同时"跑,cpu 资源按时间分片,分配给不同的进程/线程,以达到多任务的效果, 它是并发的基础。而我们熟知的异步, 和并发的概念是不同的,异步是一种编程模型,是相对于同步来讲的。在同步的情况下,函数完成任务之后返回,那相对应的,异步的情况是,函数没有完成就直接返回了,之后函数会继续完成这个任务,那调用者如何得知被调用者是否完成了呢?可以通过轮询,事件通知,回调的方式。与同步异步相伴的是阻塞和非阻塞,区别是,同步异步是相对于被调用者而言的,而阻塞和非阻塞是相对于调用者而言的。
4 A(调用者)打电话问 B(被调用者), 你的生日是什么时候? A 一直在等 B 的答复(阻塞),B 觉得自己要想很久,于是先告诉 A(任务未完成就返回,异步),我想起来了会通知你,但 A 一直还在等,并未挂断电话, 也没有做其他事情。
可以看出,第 4 种是无意义的,而第 1 种在计算密集的应用里较常用,第 2 种和第 3 种在 io 密集型的应用里比较常用。
关联技术:
对于 cpu 资源,操作系统会把它按时间分片,然后分配给所有线程,不存在竞争,因为时间是不可能重叠的,不可复用的,但像内存,文件这类资源,是没办法按时间分片的,在并发的时候就有可能产生数据竞争(data race)。
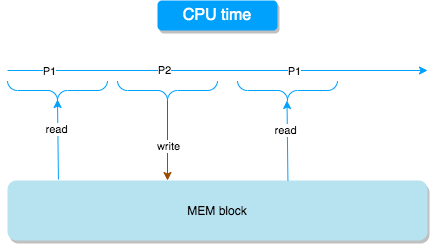
如图所示,P1, P2 相当于"同时"在访问这个内存块,因为 P1 的读还未结束,P2 就开始修改它了。因此,我们需要对资源加锁,保证 P1 在完成读之前,P2 是是不能写的。
真正的并行需要增加多个'时间线', 即多核, 每个核是独立的时间线。但多核也会让内存等不能按时间分片的资源更容易产生竞争, 处理起来也更复杂。在多核的情况下,我们可以对内存这类资源分片来减少共享数据,比如找数组的最大值,先将数组分成多份,然后合并结果。
MYSQL 数据库在处理事物并发的时候,会使用 MVCC. MVCC 用一种多版本的方式来消除数据竞争,可以理解为它通过创造多个时间线来达到数据并行。
关联技术:
我们经常会听到分布式架构, 但分布式(distribution)和去中心化(decentralize,也可以称非集中式)不是一个概念。分布式是指整个系统被分散到不同的位置,用来提升性能或者提高可靠性(比如 git),而去中心化指的是不存在一个单一的管理实体去管理整个系统,去中心化依赖多个相互独立的管理实体共同管理整个系统。SDN 是中心化(也称集中式)的,区块链是去中心化的,也是分布式的。
关联技术:
之所以将 cache 作为核心概念,一是,它很重要,无处不在,二是,我不能很快地在现实世界中找到同样的案例,因此没把它归类到 emulation 里。
我们通常接触到的 cache 是我们的内存,它的读写速度比磁盘快很多,但也很贵,存储容量有限。cache 就是在容量和性能之间做的一个较好的权衡,用较小的代价,换取可观的性能收益。它的理论基础可以认为是:
此为局部性原理。
在此类有性能差的软硬件之间,就可以设置 cache 层,来达到一个不错的效果。比如:
CPU cache CPU 的性能相对主存(main memory, 即我们熟知的内存)要快很多,如果 CPU 直接访问主存,会浪费 CPU 的性能,而 CPU 所使用的 cache (Static RAM)是比主存快的多的硬件(Dynamic RAM), 而且有多级的 cache。当然,这种高速 cache 的容量是有限的,如果未命中(miss) ,cpu 会直接访问主存。 GPU cache 和 CPU cache 的架构类似,但是是针对 3 维数据,纹理数据等做了优化的。 Disk cache 磁盘也有 cache ,也是为了弥补内存和磁盘之间性能差距的,能够大幅提高磁盘的读写速度。
**buffer 又是是什么?和 cache 有什么区别? **
从字面上理解,buffer 是缓冲,而 cache 是缓存。cache 一般用来提高 io 速度,而 buffer 一般用来提高 io 吞吐效率。buffer 一般是用来提高写效率,cache 一般用来提高读效率。之所以放在一起,是因为它们的功能是一样的,都是为了填补性能鸿沟。
Disk cache 有时候也被称为 disk buffer, 可见它们之间的渊源。
当一些数据不能马上被拿走或消费掉的时候(生产者生产的速度大于消费者消费的速度),就需要用 buffer,比如消息队列,它可以提高业务处理不过来的时候的响应速度。再如,数据库里使用的 WAL 技术,也可以认为是一种基于文件的 buffer, 提供持久性的同时,用顺序 io 代替随机 io 以提高写入速度。
关联技术:
代码复用(code reuse),连接池(connection pool),线程池(thread pool) 这些都是复用(reusing)里的经典案例。我们要思考的是,它们的共性是什么。 当我们创建, 维持或销毁一个对象,需要付出较高的代价时,我们就可以考虑复用它,现实生活中的垃圾回收再利用,也是同样的道理。 代码复用是因为创建代码的成本很高;tcp 连接的创建和销毁要经过三次握手和四次挥手,在高并发的场景里,这种消耗也是遭不住的,所以, 用完的连接可以放进连接池,等待下一次请求时使用;线程的创建,维持以及销毁都需要较高的代价,所以处理方式也是类似的。
Multiplexing 的字面意思也是复用,但多指 多路复用 。我们可以尝试用高速公路来理解它们之间微秒的区别,reuse 指公路本身可以重复再利用,而 multiplexing 指的是高速公路双向 8 车道这种特性,多个活动同时发生。常见的多路复用是 io 多路复用(io multiplexing),在理解上和公路的例子稍稍有些偏差,更多的是指将多个活动汇聚在一起处理, 这样上层逻辑可以在一个线程里处理多个活动(socket)。
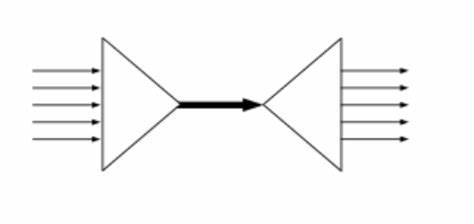
上图是 io 多路复用的模型图,可以看出,多个活动被汇聚到了一个管道去处理。
关联技术:
backup 一般指数据备份,replication 一般指副本,可能是数据副本,可能是服务副本。副本一般用来做高可用,主挂了,副本可以接管主来继续服务,而 backup 一般是用在数据丢失的情况下恢复数据或者把存储不下的数据放在另外的地方以作备用,不会直接接替主去服务。
副本的概念会经常出现在分布式数据服务里,使用副本技术,可以达到高可用的目的。