作者: songtianyi 2018-08-17
我们公司有一款软件产品 NAP(Network Automation Platform),它的主要功能是管理各类厂商(cisco, juniper, checkpoint, hillstone 等)的防火墙设备上的配置。防火墙的配置包括网络(地址)对象/服务对象/策略/NAT 规则等, 所谓的管理就是基本的 CRUD。要对其管理,第一步是解析它,第二步是对其建模,第三步是提供操作接口。解析这里不讲,本文重点探讨的是第二步中的建模方法。在此之前,我们先设想一下第三步,我们的操作接口该如何设计呢?一,针对每个厂商提供一套操作接口,但这么做的话,这套软件的学习成本很高,除了批量自动下发配置,对于网络管理员来说似乎没有其它吸引力了;从开发的角度讲,前端设计表单的工作量也会很大。二,针对所有厂商提供一套操作接口,这样网络管理员/职能部门的使用者的学习成本会小很多。显然要采用第二种方式,这就回到了第二个步骤,如何通过建模来解决这个问题。
在定义上,数据抽象(data abstraction)指的是建模这种行为,但此处用来指代一种建模的方式。我们以设备上的地址配置为例,用代码来说明这种方式。
object network range-net
range 192.168.1.110 192.168.1.111
description demo data for range type network
object network host-net
range 192.168.1.112
description demo data for host type network
object network subnet-net
range 192.168.1.0 255.255.255.0
description demo data for subnet type network
object network fqdn-net
fqdn www.google.com
description demo data for fqdn type network
在 cisco 里有四种地址表示方式,在生产环境当中它们都很常见。这种非格式化的配置我们称为 raw 配置。
set security address-book global address range-net description "demo data forrangetypenetwork"
set security address-book global address range-net range-address 192.168.1.110 to 192.168.1.111
set security address-book global address subnet-net description "demo data for subnet type network"
set security address-book global address subnet-net wildcard-address 192.168.1.0/24
set security address-book global address fqdn-net description "demo data for fqdn type network"
set security address-book global address fqdn-net dns-name www.google.com
set security address-book global address-set addSet1 address server-1
set security address-book global address-set addSet1 address server-2
juniper 有三种地址表示方式,没有 cisco 中的 host 地址。
对于这两种厂商的地址建模是很简单的, 先看下它们的 json 表示,第一个是 cisco 的,第二个是 juniper 的。
[
{
"id":"uuid",
"name":"range-net",
"description":"demo data for range type network",
"value":{
"start":"192.168.1.110",
"end":"192.168.1.111"
}
},
{
"id":"uuid",
"name":"host-net",
"description":"demo data for host type network",
"value":{
"address":"192.168.1.112"
}
},
{
"id":"uuid",
"name":"subnet-net",
"description":"demo data for subnet type network",
"value":{
"address":"192.168.1.0",
"mask":"255.255.255.0"
}
},
{
"id":"uuid",
"name":"fqdn-net",
"description":"demo data for fqdn type network",
"value":{
"name":"www.google.com"
}
}
]
[
{
"id":"uuid",
"name":"range-net",
"description":"demo data for range type network",
"value":{
"start":"192.168.1.110",
"end":"192.168.1.111"
}
},
{
"id":"uuid",
"name":"subnet-net",
"description":"demo data for subnet type network",
"value":{
"address":"192.168.1.0/24",
}
},
{
"id":"uuid",
"name":"fqdn-net",
"description":"demo data for fqdn type network",
"value":{
"name":"www.google.com"
}
}
]
你会发现,在模型上它们是没有差异的:
public class Address {
protected String id;
protected String name;
protected String description;
protected Object value;
}
Address 模型既可以表示 cisco 的地址又可以表示 juniper 的地址。这样,我们的 api 接口关于地址的输入/输出都可以使用此模型。利用不同厂商设备配置之间的数据共性,建立一个统一的模型,这种数据建模方式我们称之为数据抽象。以此类推,对于服务对象/策略等配置,也采取同样的建模方式, 那么数据流可以简单表示为:
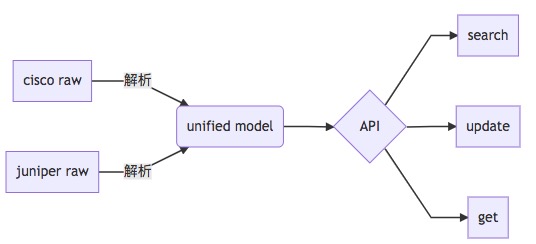
为了方便描述,这里给它取个名字 N2U
按照数据抽象的方式,我们只需要一套模型就可以表示所有厂商的配置,似乎很完美,大功告成?然而并不是。我们一开始也以为是,因为通常我们使用的防火墙的协议栈都是 TCP/IP, 它们的配置无非就是五元组, 能差到哪儿去?这里举三个例子来说明它们之间的差异。一,细心的人会发现,我们在用 Address 来表示 juniper 地址的时候丢掉了一个信息 global, global 是一个特殊的地址簿名称,代表全局地址簿,除此之外,juniper 还有带 zone 信息的地址,global 地址和 zone 地址之间,cisco 地址和 juniper 地址之间,必然是无法完美统一的。二,在 cisco 的地址组或者策略中,你可以定义一个临时地址,或者叫内建地址, 也可以以名称引用一个定义好的地址对象:
object-group network netgrp
network-object host 192.168.1.110 // 内建地址
network-object object host-net // 直接引用地址对象
而在 juniper 中,不管是地址组还是策略都是以名称来引用的,没有内建的形式。三,juniper 的 NAT 规则和 cisco 的 NAT 规则,在定义方式和数据的结构两方面的差异都很大,cisco 可以在地址对象里定义 NAT 规则,juniper 不可以,cisco 的一条 NAT 配置就是一条规则,而 juniper 则是一个 set。渐渐地,你会发现设备之间的配置差异很大,好像除了五元组没有什么是相同的。另外,对于配置的约束条件,比如地址名称的格式,地址组的最大地址数等,不同设备之间也有差异。由于不同厂商设备配置携带的信息量是有差异的,因此几乎每个厂商都需要一套自己的模型,才能保证在建模的时候不丢失信息,那么这种形式的数据流(命名为N2N)可以简单表示为:
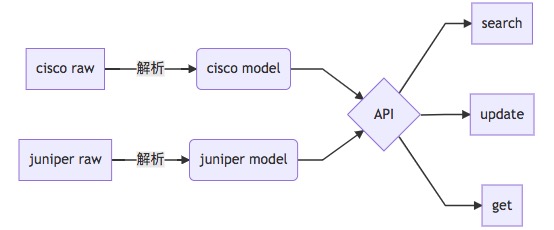
在前言中我们提到过,不管后台的逻辑多复杂,我们暴露给用户的接口都应该尽量简单,所以上面的图中只有一个 API。这样自然会有一个问题,比如 api 提供的策略搜索功能, 在上述数据流的情况下,需要编写两个函数来分别处理 cisco 和 juniper 的配置:
List<Policy> search(CiscoConfig) {}
List<Policy> search(JuniperConfig) {}
考虑到 api 层逻辑的代码编写量,我们最终还是定义了一套统一的模型来解决这个问题,数据流(取名为N2N2U)可以简单表示为:
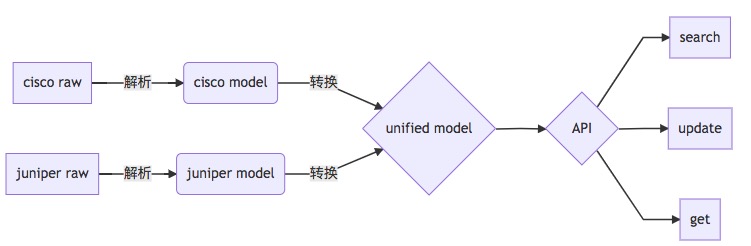
这样业务逻辑只需编写一次:
List<Policy> search(UnifiedConfig) {}
但结果并不好,因为我们从 cisco model 和 juniper model 到 unified model 这一步是需要进行模型转换的。从目前的实践经验来看,unified model 并没有帮我们降低整体的代码复杂程度和代码量,反而带来了大量的模型抽象和模型转换的工作量,以及出错的机会。采用虚拟模型的另外一个原因是考虑到分工协作,写 API 逻辑的人只需理解一套规则即可,在这一点上目前还不好下定论。总体来说,N2N2U 的方式会随着厂商类别越来越多而难以为继。此外,上述三种方式都存在着一个弊端。我们在定义 Address 的时候使用了 Object 类型(你也可以用泛型),http 请求到达后端并经过框架处理后,我们拿到的这个 Object 并不是最终我们能使用的模型。
比如我们用 RangeValue 来表示 start..end 结构:
public class RangeValue {
protected String start;
protected String end;
}
前端的输入为:
{
"id":"uuid",
"name":"range-net",
"description":"demo data for range type network",
"value":{
"start":"192.168.1.110",
"end":"192.168.1.111"
}
}
我们拿到的模型实例的 value 字段是一个 LinkedHashMap , 而不是 RangeValue , 此时需要将 LinkedHashMap 转成 RangeValue , 但是缺乏足够的信息。最直接的方法是一个个地尝试,总共就四种类型,最多尝试四次即可达到目的,另外一个方法是在模型中加入类型信息:
{
"id":"uuid",
"name":"range-net",
"description":"demo data for range type network",
"type":"RANGE",
"value":{
"start":"192.168.1.110",
"end":"192.168.1.111"
}
}
这样也可以达到目的。虽然如此,但在实际当中我们并不把这样的模型作为输入模型,因为提供给用户的接口要尽可能地简单,除非需要用户指定所有的信息。大部分时候我们只需传入一个 String :
{
"address":"192.168.1.110~192.168.1.111"
}
针对上述的种种问题,我们需要尝试换一种方式, 即接口抽象来解决它们。接口抽象是针对数据的功能/用途/用法来抽象。比如搜索功能,我们可以分别为 CiscoConfig 和 JuniperConfig 实现一个搜索接口。
public interface ConfigInterface<T> {
List<Quintuple> search(Quintuple);
...
}
public class CiscoConfig implements ConfigInterface<CiscoConfig> {
@Override
public List<Quintuple> search(Quintuple) {...}
}
public class JuniperConfig implements ConfigInterface<JuniperConfig> {
@Override
public List<Quintuple> search(Quintuple) {...}
}
按照这种方式,修改后的数据流(取名为N2NI)简单表示为:
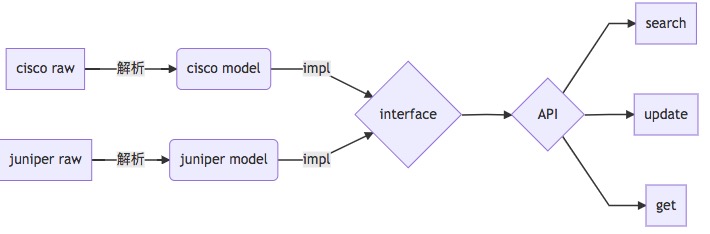
通过图形化的对比我们发现,工作量的差异主要在实现业务逻辑接口的工作量和模型抽象及转换的工作量之间。业务逻辑需要实现 N 次,模型抽象需要 N 次,模型转换也需要 N 次,N 为厂商的类型个数。
对于厂商 raw 配置的模型抽象,我们可以定义一些公共类,比如之前定义的 RangeValue , 还有用来表示地址的 WildcardValue 等等:
public class WildcardValue {
// 192.168.1.0/24
protected String address;
}
公共类可以显著减少我们的工作量。在实践当中,对于继承的运用很少,因为基类信息太少,且属性的约束/书写形式也不太一样,比如 cisco 和 juniper 的两种地址表示形式:
192.168.1.0/24
192.168.1.0 255.255.255.0
通常在定义模型的时候,我们会自然而然地采用层级结构:
public class A {
protected B b;
}
public class B {
protected List<C> cs;
}
public class C {
protected String value;
}
层级结构的模型看起来会更简洁,更符合我们的思维方式。
层级结构也存在自身的问题,我们在使用 value 的时候会很麻烦:
A a = new A();
a.setb(...);
...
a.getb().getcs().get(0).value();
尤其是当 B 或者 C,甚至 B 和 C 都是泛型/Object 的时候,对于复杂的对象,模型可能会达到 5 个以上的层级。在实践中我们发现,数据在业务逻辑之间流动的时候,往往并不需要全部的信息,我们的功能关注的主要数据就是五元组。比如策略搜索,输入是五元组,判断逻辑使用的也是五元组,判断地址时并不需要 name , description 等字段,那么我们是否可以将这些关键信息放在第一层级?按照这种方式, 我们尝试重新定义一下 Application 模型。原模型为:
// level 1
public class Application {
protected String id;
protected String name;
protected String description;
protected List<TermValue> terms;
}
// level 2
public class TermValue {
protected String name;
protected ProtocolType protocol;
protected T value;
}
// level 3
public class IcmpValue {
protected String type;
protected String code;
}
// level 3
pubilc class NonIcmpValue {
protected PortType type;
protected T value;
}
// level 4
public class SinglePortValue {
protected Integer port;
}
// level 4
public class RangePortValue {
protected Integer start;
protected Integer end;
}
修改后的模型为:
// level 1
public class Application {
protected String id;
protected String name;
protected String description;
protected List<IcmpValue> icmps;
protected List<NonIcmpValue> nonIcmps;
}
// level 2
public class IcmpVlue {
protected String name;
protected String type;
protected String code;
}
// level 2
public class NonIcmpValue {
protected String name;
protected Integer start;
protected Integer end;
}
这样我们把 4 个层级的模型抽象到了 2 个层级, 简化了数据的存取。
并没有一个非常完美的方式,来解决模型抽象中的问题,这是厂商配置之间差异导致的必然结果,也是我们产品的价值所在,我们需要在这多种抽象方式之间做权衡,在实践中找到那个平衡点。