作者: songtianyi create@2020/12/26
声明: 本文所讲的内容中的部分细节也许并不是十分准确的,这是属于我的学习方法,先弄清楚基本概念,不去扣实现细节。
大部分时候,我们是不需要关心这些事情的,数据库安装,初始化,建表之后,我们就可以安逸地进行 CRUD 了。但我们也知道,基础理论是一个绕不开的话题,如果你要针对业务做一些优化,那就逃不开了。另外, 业务总是在变化,技术也会被业务驱动着去演进。mongodb,redis,time-series db 等等,这些都是因为业务变化而带来的技术更迭。这些变化是我们的负担,我们需要不停地学习新的知识,但更是我们的机会,如果你能在业务变化之前掌握好基础理论,那么在业务变化之时,你才能走在最前沿,去创造一些新的东西。否则,只能写一辈子 CRUD 了。
好了,我们现在弄明白了为什么学,那么继续看看怎么学。
在学习技术之前,搞清楚它的需求背景是及其重要的,不然只能知其然,而不知其所以然。首先,我们得明白一个道理,不管是写业务还是写底层组件,我们写的代码有很多是为了处理异常情况的,比例从 20% 到 %50 不等。
先来看一个简单的例子。
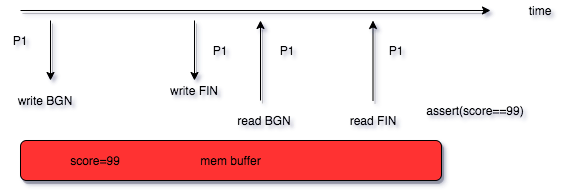
不考虑并发,程序将 score 的值修改为 99 之后,读到的值应该是 99 才是符合预期的对吧,这是正常的情况。
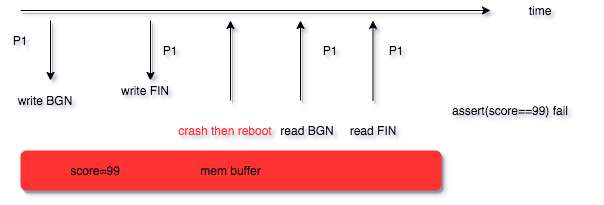
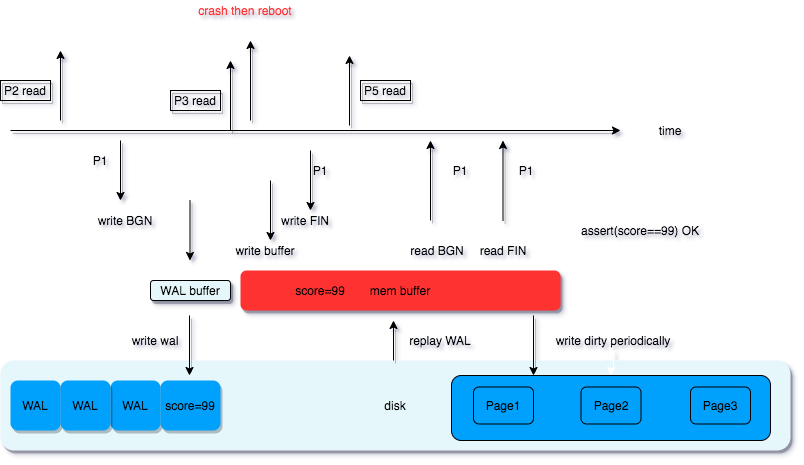
那么假如 score 被修改为 99 之后,程序崩溃或者机器宕机了怎么办?因为性能的原因,数据库在写入数据的时候是先写到内存,然后刷到磁盘的,那么还未刷入的磁盘的部分,是不是就丢了?
数据库事务,可以认为是解决这些杂七杂八问题的技术组合。在讲之前,我们先抛弃这些概念性的东西,回归到数据库的本质,即数据库设计的目标是什么?用一个大的概念来讲就是 可靠性 。数据库系统在经受硬件故障,软件故障,人为错误的“袭击”后,能够恢复到正常状态。而可靠性的背后又包含了方方面面的东西。
数据库事务(Transaction)一般指数据库所满足的 ACID 特性,即 原子性(Atomic), 一致性(Consistency), 隔离型(Isolation), 持久性(Durablility). 大多数文章都是按照这样的顺序去讲这些概念以及背后的技术,我习惯从场景出发,然后按照常人的思路逐步展开,浅入浅出,所以这里暂时不介绍这些概念的具体定义。
先来看数据库怎么解决程序崩溃或者机器宕机导致的数据丢失问题。思路也很直接,既然写在内存里会丢,那就写到文件。不过我们前边提到,数据库不直接写文件,是因为写磁盘的效率比写内存的效率低很多,那怎么办呢?
WAL 称为预写入日志,也叫 redo log, 数据库的所有修改会先写入到 WAL 和内存 buffer (先不考虑谁先谁后),而 WAL 是写入到磁盘里的,程序崩溃重启后,重放(replay)WAL 就可以恢复 buffer 内的数据。
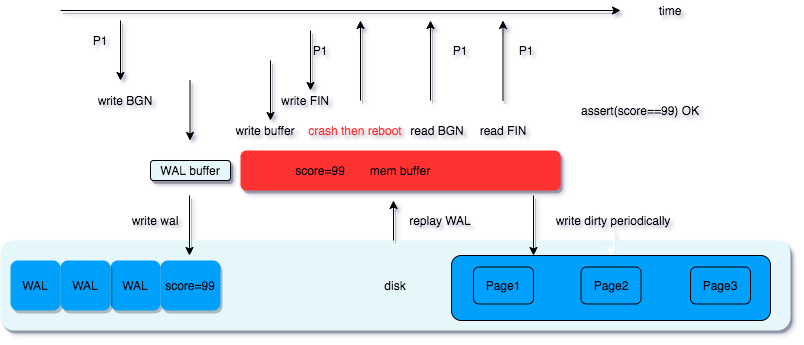
这一点比较好理解,关键在于,为什么同样是写文件到磁盘,WAL 比直接将数据写入到磁盘快呢。WAL 本质上也是一个缓冲区,只不过它是放在磁盘上的,保证了可靠性。
这里补充一个额外的小知识点,物理磁盘为了提高读写的效率,也会有自己的缓冲区,注意写磁盘的时候是写到了磁盘缓冲还是真正写到磁盘上了。
WAL 实际的实现比图中展示的要复杂的多,但这里并不展开。
显然,WAL 保障了数据库的持久性(Durablility)。持久性意味着,当数据库告诉你该次操作是成功的,那么即使数据库重启,数据库的状态也是写入后的状态。
WAL 文件肯定是不能无限增长的, 一般一个 WAL 文件,最多建议 2 个,内存 buffer 也有上限。那么什么时候 记录在 WAL 中的数据库操作会被写入到磁盘呢?数据库系统中有一个 checkpointer 的子进程,它会定期的做条件检查,当满足条件的时候就会做这件事(比如,距离上一次 checkpoint 已经过去了 5 分钟),将内存的 dirty data 写入到磁盘,除此之外,超级管理员也可以通过 CHECKPOINT 命令手动触发 checkpoint 操作。
完成后会添加一个 checkpoit 标记,方便找到 WAL replay 的起始位置。
一旦涉及到并发,复杂程度就立马上几个级别。
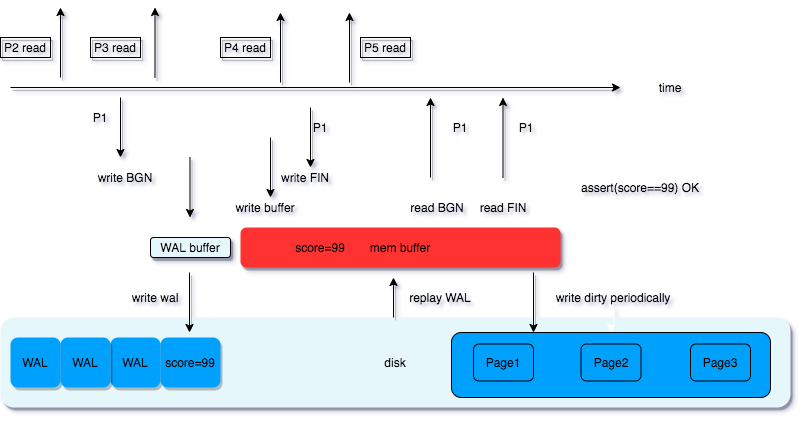
先看上图,P2 和 P5 的读到的结果是确定的,P2 读到的是 score 修改前的值,P5 读到的是修改后的 99, 那么 P3, P4 呢?是不是就没那么好确定了。此时,就要看我们的业务是否需要 P3, P4 读到的结果是一致的。如果我们在业务逻辑中去考虑这个问题,负担是很大的,很容易导致奇奇怪怪的不符合预期的情况出现。
假如我们有如下的业务逻辑, 即,如果分数等于 99,程序输出 excellent!
// 伪代码
func increase(x int) {
s := read_score()
if when s == 99 {
print "excellent!"
}
}
如果这段代码在两台不同的机器上同时执行,输出的结果是不能保证是一致的。
我们考虑的复杂一点,如下图:
假如 P3 读的时候 WAL 已经写入完成,但是内存 buffer 还未写入,之后程序 crash 了,那么 P3 和 P5 读到的值也是不一致的。这种情况被定义为 Read Uncommitted, 即脏读。
如果我们把分数换成金额,那么问题就很严重了。针对这类情况,数据库提供了锁的机制。
我们可以对写操作加锁,P3 只能在 P1 结束之后读取,这样 P3 和 P5 读到的数据才是一致的。数据库给我们的这种保证称为 Read Committed.
有了写锁,我们就能应对大部分的业务问题了。但有时候,我们也需要 P2 和 P5 读到的数据是一致的。
// 伪代码
func compare(students []int) {
for i, s := range students {
x := read_score()
if s > x {
print "student “ + i + " excellent!"
}
}
}
例如,我们有上面的业务逻辑,假设 score 在被修改之前是 98, 且 students 内的值包含两个 99,[..., 99, ...., 99, ...] 你会看到,同样为 99 的分值的不同学生,他们最后得到的输出结果可能是不相同的,出现了不公平的结果。这种情况被定义为 Nonrepeatable Read, 即不可重复读。
同样的,我们也可以对读操作加锁,在读的时候不允许写,这样 P2 和 P5 读到的数据一致,从而保证最终的业务结果是符合预期的。数据库给我们的这种保证称为 Repeatable Read, 即, 可重复读。
读到这里,大家会有些迷糊,P2 读结束之后,锁释放了,P1 就可以写数据了,那 P5 读到的仍然是修改后的数据,怎么就一致了呢?
ok,带着这个疑惑,我们将正式引入数据库事务的概念。
先回到上面的例子,如果我们要保证结果是符合预期的,我们可以这么做。
// 伪代码
func compare(students []int) {
db_transaction_begin() // 对数据库加读锁
for i, s := range students {
x := read_score()
if s > x {
print "student " + i + " excellent!"
}
}
db_transaction_end() // 释放数据库的读锁
}
这样,结果一定是符合预期的。那么 begin 和 end 之间的多次 read_score 的操作就是数据库的一次事务中的操作序列。beign 是事务的开始,end 是该次事务的结束。
接着看下面的逻辑, 假如我们要将一些学生的分数批量写入数据库:
// 伪代码
func batch_write(students []int) {
for i, s := range students {
write_score(i, s)
}
}
这样是没问题的,对吧?如果半路程序崩了,我们查下写入到了第几个学生,然后再接着那个位置再执行一遍就可以了,只是有些麻烦。
// 伪代码
func batch_write(students []int) {
for i, s := range students {
async {
is_female := rpc(s)
is_minority := rpc(s)
if is_female && is_minority {
write_score(i, s+10)
}
}
}
}
比如上面的代码, 针对少数民族的女生加 10 分的逻辑,假如程序在执行过程中崩溃了,那我们是很难通过重新执行程序达到最终结果的,也不可能像之前的例子一样去手工纠正。
而有了数据库事务,我们就可以这么写。
// 伪代码
func batch_write(students []int) {
db_transaction_begin() // 对数据库加写锁
for i, s := range students {
async {
is_female := rpc(s)
is_minority := rpc(s)
if is_female && is_minority {
write_score(i, s+10)
}
}
}
db_transaction_end() // 释放数据库的写锁
}
如果事务在执行完成之前程序崩溃,那么重启之后,数据库还是事务开始前的状态,因为只有在事务结束后才会写 WAL,这样我们重新再跑一遍程序就好了。这种数据库特性称为原子性(Atomicity), 将多个的操作序列合并到一个事务级别的原子操作里,该事务中的操作序列要么被全部执行,要么全部不执行。数据库事务除了保障业务之外,也避免了频繁的加解锁操作,对数据库读写性能的提升也很有帮助。
我们前边已经讲了锁的概念,但读锁和写锁之间的组合不单单只有我们提到的那几种,再加上锁的范围,以及锁的周期会更加复杂,这里专门梳理一下。
在数据库里是有专门的概念来概括的,即事务的隔离级别,这种数据库的隔离特性称为 Isolation,事务的隔离性可以让所有的事务的执行看起来像是顺序执行的一样,和我们处理并发的道理是一样的,在并发的同时,不破坏业务的逻辑顺序,同样的,数据库事务在并发执行的时候,业务的逻辑顺序也需要被保障。这种隔离级别的细分,让我们可以根据业务需求来调整,以求在满足业务需要的前提下取得更好的读写性能。
Read Uncommitted
允许读取未提交内容
对正在被修改的行加锁,修改完立即释放;对正在被读取的行加锁,读取完立即释放。可以理解为事务是没加锁的,只是单纯的并发锁。
Read Committed
只允许读取已提交的内容
对正在修改的的行加写锁, 直到事务结束,读时允许写。该级别可能会出现,同一事务中的不同次读操作读到的数据不一致。大多数数据库都默认为此级别。
Repeatable Read
可重读
在 Read Commited 的基础上,对正在读取的行加读锁,不允许修改,直到事务结束。如果读锁是行级别的,可能会出现,同一个事务中,一开始读到的行数和后来读到的行数不一致。
比如:
select count(*) from t where type="x";
此时,被选中的行是加锁的,不允许修改,但新增行是可以的,那么第二次读的时候就会多出来新增部分的行。
Serializable
可串行化
读加锁,写加锁,读写互斥,而且是表级锁。当然这种方式的性能是很低的。
以上只是简单形式的锁组合以及锁范围,目的只是为了说明事务的隔离级别,实际情况会更复杂。感兴趣的可以看看 MVCC (多版本并发控制)
既然提了一嘴就简单说几句,MVCC 全称 Multi-Versioned Concurrency Control。主要是为了解决事务并发时的锁的效率问题,简单来说就是该加的锁加了,不该加的锁不加, 既保证业务的逻辑顺序,又有良好的读写速率。
回顾前面的内容,在 Repeatable read 的隔离级别下,我们对所有的涉及到的行加读锁,不允许写,这种锁属于悲观锁。那么相对地,乐观锁怎么做呢?所谓的乐观,指的是对数据的修改, 在业务逻辑的层面上,不影响我们已经开始的读操作,不需要总是读取到最新的数据,即读的时候允许对数据修改,但同时要保证可重复读的性质。
MVCC 通过引入版本链的方式来解决读写并发的冲突,达到读的时候可以写,写的时候可以读的效果。简单来讲,一个读事务开始时,我们记录当前版本的 id,之后一直读该版本的数据,保证可重复读的 性质,如果在读事务结束前,有一个写事务要开始,我们把修改数据的版本,在新的版本上执行写操作,这样就不会影响到之前的读事务。如果写事务失败,可以根据 undo log 回滚。
undo log 主要记录事务结束之前的操作,当事务失败进行回滚,这和 redo log 是相反的,redo log 或者说 WAL 是记录事务成功后的整个事务操作记录。