
作者: songtianyi create@2020-01-31
版权声明: 部分内容复制自网络,如有侵权,请联系本人删除
这篇文章是我学习区块链的过程中边学边写所形成的。
所以,本文所讲的内容并不单单指区块链本身,还包括分布式电子加密货币所需要的各种底层技术。
1990 年 8 月,Bellcore(1984 年由 AT&T 拆分而来的研究机构)的 Stuart Haber 和 W. Scott Stornetta 在论文《How to Time-Stamp a Digital Document》中就提出利用链式结构来解决防篡改问题,其中新生成的时间的证明需要包括之前证明的 Hash 值。这可以被认为是区块链结构的最早雏形。 后来,2005 年 7 月,在 Git 等开源软件中,也使用了类似区块链结构的机制来记录提交历史。 区块链结构最早的大规模应用出现在 2009 年初上线的比特币项目中。在无集中式管理的情况下,比特币网络持续稳定,支持了海量的交易记录,并且从未出现严重的漏洞,引发了广泛关注。这些都与区块链结构自身强校验的特性密切相关。
区块链的目标是实现一个分布式的数据记录账本,这个账本只允许添加、不允许删除。账本底层的基本结构是一个线性的链表。链表由一个个“区块”串联组成(如下图所示),后继区块中记录前导区块的哈希(Hash)值。某个区块(以及块里的交易)是否合法,可通过计算哈希值的方式进行快速检验。网络中节点可以提议添加一个新的区块,但必须经过共识机制来对区块达成确认。
我们知道,区块链是比特币的技术实现的基础,那么一个交易过程是如何运用到区块链的呢?
在上图的基础上,我们发起一笔交易,这笔交易将账户 A 的余额减少 3, 账户 B 的余额增加 3, 将交易信息放进 block 的 transaction 结构里,并添加上一个 block 的 hash 值到当前的 block 里,构造好这个 block 结构之后,广播出去,这样整个网络中的节点都会收到该交易请求,然后将这个记录添加到这个链式结构里。

问题是,如何判断这个交易是否合法?
区块链的另一个核心特性是,账本是存在分布式的节点里的,这些节点相当于一个数据库,那么就会遇到分布式所带来的经典问题,比如一致性怎么保证?
一致性指的是,某个节点的数据发生了变更,在其它节点也能立即看到这个变更,但这是不可能的,数据的同步需要一个过程,假如有部分节点宕机了呢?有些节点不承认这个变更呢?所以,大部分情况下我们实现的都是最终一致性。比如,这个变更在某几个节点完成了,就认为这个变更成功了,剩下的节点会逐步同步这个变更,在这个期间,如果还未同步的节点基于旧的数据进行有冲突的变更,最终会失败。
以 12306 购票来举例,我们在刷票的时候看到了余票,当我们选中并提交的时候,系统可能会提示无票,因为在我们看到余票和提交购票请求的这个短暂的时间内,已经有人把票锁定了。
从某个节点的变更(更通用的说法是 Proposal)到节点达成一致的过程是由共识(Consensus)算法来完成的。
理论上,如果分布式系统中各节点都能以十分“理想”的性能(瞬间响应、超高吞吐)稳定运行,节点之间通信瞬时送达(如量子纠缠),则实现共识过程并不十分困难,简单地通过广播进行瞬时投票和应答即可。 可惜地是,现实中这样的“理想”系统并不存在。不同节点之间通信存在延迟(光速物理限制、通信处理延迟),并且任意环节都可能存在故障(系统规模越大,发生故障可能性越高)。如通信网络会发生中断、节点会发生故障、甚至存在被入侵的节点故意伪造消息,破坏正常的共识过程。
一般地,把出现故障(Crash 或 Fail-stop,即不响应)但不会伪造信息的情况称为“非拜占庭错误(Non-Byzantine Fault)”或“故障错误(Crash Fault)”;伪造信息恶意响应的情况称为“拜占庭错误”(Byzantine Fault),对应节点为拜占庭节点。显然,后者场景中因为存在“捣乱者”更难达成共识。
此外,任何处理都需要成本,共识也是如此。当存在一定信任前提(如接入节点都经过验证、节点性能稳定、安全保障很高)时,达成共识相对容易,共识性能也较高;反之在不可信的场景下,达成共识很难,需要付出较大成本(如时间、经济、安全等),而且性能往往较差(如工作量证明算法)。
根据解决的场景是否允许拜占庭错误情况,共识算法可以分为 Crash Fault Tolerance (CFT) 和 Byzantine Fault Tolerance(BFT)两类。
对于非拜占庭错误的情况,已经存在不少经典的算法,包括 Paxos(1990 年)、Raft(2014 年)及其变种等。这类容错算法往往性能比较好,处理较快,容忍不超过一半的故障节点。
对于要能容忍拜占庭错误的情况,包括 PBFT(Practical Byzantine Fault Tolerance,1999 年)为代表的确定性系列算法、PoW(1997 年)为代表的概率算法等。确定性算法一旦达成共识就不可逆转,即共识是最终结果;而概率类算法的共识结果则是临时的,随着时间推移或某种强化,共识结果被推翻的概率越来越小,最终成为事实上结果。拜占庭类容错算法往往性能较差,容忍不超过 1/3 的故障节点。
此外,XFT(Cross Fault Tolerance,2015 年)等最近提出的改进算法可以提供类似 CFT 的处理响应速度,并能在大多数节点正常工作时提供 BFT 保障。
Algorand 算法(2017 年)基于 PBFT 进行改进,通过引入可验证随机函数解决了提案选择的问题,理论上可以在容忍拜占庭错误的前提下实现更好的性能(1000+ TPS)。
FLP 不可能原理:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法(No completely asynchronous consensus protocol can tolerate even a single unannounced process death)。
三个人在不同房间,进行投票(投票结果是 0 或者 1)。彼此可以通过电话进行沟通,但经常有人会时不时睡着。比如某个时候,A 投票 0,B 投票 1,C 收到了两人的投票,然后 C 睡着了。此时,A 和 B 将永远无法在有限时间内获知最终的结果,究竟是 C 没有应答还是应答的时间过长。如果可以重新投票,则类似情形可以在每次取得结果前发生,这将导致共识过程永远无法完成。
FLP 原理实际上说明对于允许节点失效情况下,纯粹异步系统无法确保共识在有限时间内完成。即便对于非拜占庭错误的前提下,包括 Paxos、Raft 等算法也都存在无法达成共识的极端情况,只是在工程实践中这种情况出现的概率很小。
这就是科学和工程不同的魅力。FLP 不可能原理告诉大家不必浪费时间去追求完美的共识方案,而要根据实际情况设计可行的工程方案。 那么,退一步讲,在付出一些代价的情况下,共识能做到多好?
回答这一问题的是另一个很出名的原理:CAP 原理。
CAP 原理:分布式系统无法同时确保一致性(Consistency)、可用性(Availability)和分区容忍性(Partition),设计中往往需要弱化对某个特性的需求。
一致性、可用性和分区容忍性的具体含义如下:
CAP 原理认为,分布式系统最多只能保证三项特性中的两项特性。
比较直观地理解,当网络可能出现分区时候,系统是无法同时保证一致性和可用性的。要么,节点收到请求后因为没有得到其它节点的确认而不应答(牺牲可用性),要么节点只能应答非一致的结果(牺牲一致性)。
既然在理论上我们无法达到完美,那么在工程上,我们要尽可能地达到平衡。
Paxos 共识算法在工程角度实现了一种最大化保障分布式系统一致性(存在极小的概率无法实现一致)的机制, 其基本原理是两段提交(Two-phase Commit)算法,即将提交过程分为预提交和正式提交两步。
Paxos 里面对这两个阶段分别命名为准备(Prepare)和提交(Commit)。准备阶段通过锁来解决对哪个提案内容进行确认的问题,提交阶段解决大多数确认最终值的问题。
Paxos 算法中存在三种逻辑角色的节点,在实现中同一节点可以担任多个角色
准备阶段:
提交阶段:
2 接受者收到接受消息后,如果发现提案号不小于已接受的最大提案号,则接受该提案,并更新接受的最大提案。 一旦多数接受者接受了共同的提案值,则形成决议,成为最终确认。
Paxos 并不保证系统总处在一致的状态。但由于每次达成共识至少有超过一半的节点参与,这样最终整个系统都会获知共识结果。一个潜在的问题是提案者在提案过程中出现故障,这可以通过超时机制来缓解。极为凑巧的情况下,每次新一轮提案的提案者都恰好故障,又或者两个提案者恰好依次提出更新的提案,则导致活锁,系统会永远无法达成共识(实际发生概率很小)。
拜占庭问题(Byzantine Problem)又叫拜占庭将军(Byzantine Generals Problem)问题,讨论的是允许存在少数节点作恶(消息可能被伪造)场景下的如何达成共识问题。拜占庭容错(Byzantine Fault Tolerant,BFT)讨论的是容忍拜占庭错误的共识算法。
在大多数的分布式系统中,拜占庭的场景并不多见。然而在特定场景下存在意义,例如允许匿名参与的系统(如比特币),或是出现欺诈可能造成巨大损失的情况。
对于拜占庭问题来说,假如节点总数为 N,故障节点数为 F,则当 N >= 3F + 1 时,问题才能有解。
拜占庭容错算法(Byzantine Fault Tolerant)是面向拜占庭问题的容错算法,解决的是在网络通信可靠,但节点可能故障和作恶情况下如何达成共识。
拜占庭容错算法最早的讨论可以追溯到 Leslie Lamport 等人 1982 年 发表的论文《The Byzantine Generals Problem》,之后出现了大量的改进工作,代表性成果包括《Optimal Asynchronous Byzantine Agreement》(1992 年)、《Fully Polynomial Byzantine Agreement for n>3t Processors in t+1 Rounds》(1998 年)等。长期以来,拜占庭问题的解决方案都存在运行过慢,或复杂度过高的问题,直到“实用拜占庭容错算法”(Practical Byzantine Fault Tolerance,PBFT) 算法的提出。 1999 年,这一算法由 Castro 和 Liskov 于论文《Practical Byzantine Fault Tolerance and Proactive Recovery》中提出。该算法基于前人工作(特别是 Paxos 相关算法,因此也被称为 Byzantine Paxos)进行了优化,首次将拜占庭容错算法复杂度从指数级降低到了多项式级,目前已得到广泛应用。其可以在恶意节点不超过总数 1/3 的情况下同时保证 Safety 和 Liveness。 PBFT 算法采用密码学相关技术(RSA 签名算法、消息验证编码和摘要)确保消息传递过程无法被篡改和破坏。
拜占庭问题之所以难解,在于任何时候系统中都可能存在多个提案(因为提案成本很低),并且在大规模场景下要完成最终确认的过程容易受干扰,难以达成共识。 2014 年,斯坦福的 Christopher Copeland 和 Hongxia Zhong 在论文《Tangaroa: a byzantine fault tolerant raft》中提出在 Raft 算法基础上借鉴 PBFT 算法的一些特性(包括签名、恶意领导探测、选举校验等)来实现拜占庭容错性,兼顾可实现性和鲁棒性。该论文也启发了 Kadena 等项目的出现,实现更好性能的拜占庭算法。 2017 年,MIT 计算机科学与人工智能实验室(CSAIL)的 Yossi Gilad 和 Silvio Micali 等人在论文《Algorand: Scaling Byzantine Agreements for Cryptocurrencies》中针对 PBFT 算法在很多节点情况下性能不佳的问题,提出先选出少量记账节点,然后再利用可验证随机函数(Verifiable Random Function,VRF)来随机选取领导节点,避免全网直接做共识,将拜占庭算法扩展到了支持较大规模的应用场景,同时保持较好的性能(1000+ tps)。 此外,康奈尔大学的 Rafael Pass 和 Elaine Shi 在论文《The Sleepy Model of Consensus》中还探讨了在动态场景(大量节点离线情况)下如何保障共识的安全性,所提出的 Sleepy Consensus 算法可以在活跃诚实节点达到一半以上时确保完成拜占庭共识。 2018 年,清华大学的 Chenxing Li 等在论文《Scaling Nakamoto Consensus to Thousands of Transactions per Second》中提出了 Conflux 共识协议。该协议在 GHOST 算法基础上改善了安全性,面向公有区块链场景下,理论上能达到 6000+ tps。 比特币网络在设计时使用了 PoW(Proof of Work)的概率型算法思路,从如下两个角度解决大规模场景下的拜占庭容错问题。 首先,限制一段时间内整个网络中出现提案的个数(通过工作量证明来增加提案成本);其次是丢掉最终确认的约束,约定好始终沿着已知最长的链进行拓展。共识的最终确认是概率意义上的存在。这样,即便有人试图恶意破坏,也会付出相应的经济代价(超过整体系统一半的工作量)。 后来的各种 PoX 系列算法,也都是沿着这个思路进行改进,采用经济博弈来制约攻击者。
前面介绍和讨论了分布式环境下的一致性问题,对于区块链的应用场景来说,安全性也是一个十分大的挑战。
Hash, RSA, 证书这些概念在我以前的文章里有详细的介绍,可以略过。这里重点介绍以前还未触及的内容。
默克尔树(Merkle tree) 是一种典型的二叉树,看图就能明白, 如下:
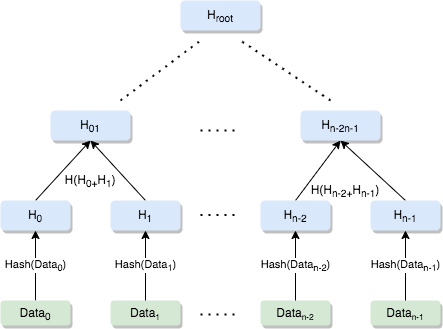
简单来说,我们可以将一个文件,拆分成 Data0... Datan-1 的 n 份小数据块,每一块分别做 hash, 计算其 hash 值, 然后相邻两块数据的 hash 值拼接(不一定是字符串拼接)在一起再做 hash 值,以此类推直到根节点,根节点被称为 Merkle root。
比较典型的应用是在 p2p 网络中,我们可以在可信源获得整个待下载文件的 Merkle root, 得到 root 的 hash 只之后,我们就可以从多个不同的数据源(可能是不可信的源)去获取数据并验证,Merkel tree 可以让我们对任意大小的数据块(任意子树)做验证。
同态加密(Homomorphic Encryption)是一种特殊的加密方法,从抽象代数的角度讲,保持了同态性。 如果定义一个运算符 △,对加密算法 E,满足:
E(X △ Y)=E(X)△ E(Y)
对解密算法 D, 同样满足:
D(X △ Y)=D(X)△ D(Y)
则意味着对于该运算满足同态性。
同态性来自代数领域,一般包括四种类型:加法同态、乘法同态、减法同态和除法同态。同时满足加法同态和乘法同态,则意味着是代数同态,即全同态(Full Homomorphic)。同时满足四种同态性,则被称为算数同态。 对于计算机操作来讲,实现了全同态意味着对于所有处理都可以实现同态性。只能实现部分特定操作的同态性,被称为特定同态(Somewhat Homomorphic)。
仅满足加法同态的算法包括 Paillier 和 Benaloh 算法;仅满足乘法同态的算法包括 RSA 和 ElGamal 算法。
目前全同态的加密方案主要包括如下三种类型:
以云计算场景为例来说明同态加密的过程, 如下:
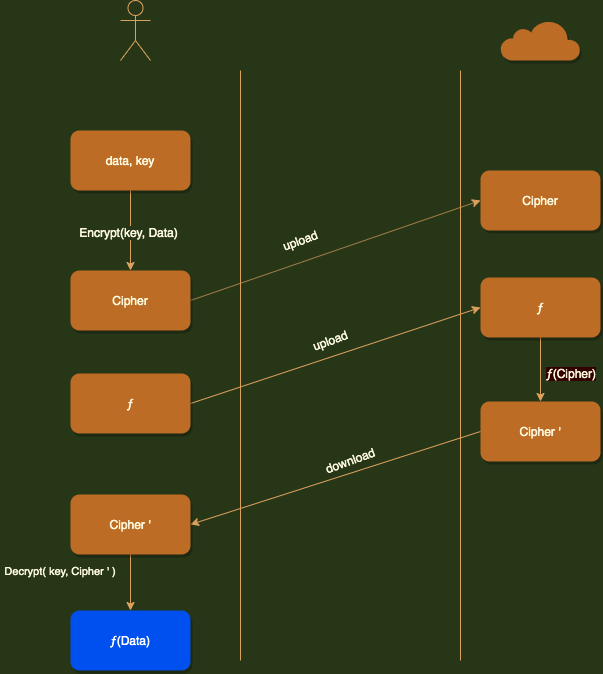
同态加密的应用场景:
同态技术在该方面的应用可以使得我们在云环境下,充分利用云服务器的计算能力,实现对明文信息的运算,而不会有损私有数据的私密性。例如医疗机构通常拥有比较弱的数据处理能力,而需要第三方来实现数据处理分析以达到更好的医疗效果或者科研水平,这样他们就需要委托有较强数据处理能力的第三方实现数据处理(云计算中心),但是医院负有保护患者隐私的义务,不能直接将数据交给第三方。在同态加密技术的支持下,医疗机构就可以将加密后的数据发送至第三方,待第三方处理完成后便可返回给医疗结构。整个数据处理过程、数据内容对第三方是完全透明的。
用户可以将自己的数据加密后存储在一个不信任的远程服务器上,日后可以向远程服务器查询自己所需要的信息,存储与查询都使用密文数据,服务器将检索到的密文数据发回。用户可以解密得到自己需要的信息,而远程服务器却对存储和检索的信息一无所知。此种方法同样适用于搜索引擎的数据检索。
所谓安全多方计算就是分别持有私有数据 x1, x2, …, xn 的 n 个人,在分布式环境中协同计算函数 f (x1, x2, …, xn) 而不泄露各方的私有数据。以同态技术加密的密文数据计算不仅可以满足安全多方计算协议设计中保护各方隐私的需要,还能避开不经意传输协议而大大提升协议效率。
基于同态加密技术设计的电子选举方案,统计方可以在不知道投票者投票内容的前提下,对投票结果进行统计,既保证了投票者的隐私安全,有能够保证投票结果的公证。
零知识证明(Zero Knowledge Proof),是这样的一个过程,证明者在不向验证者提供任何额外信息的前提下,使验证者相信某个论断(Statement)是正确的。
证明过程包括交互式(Interactive)和非交互式(Non-interactive)两种。
零知识证明的研究始于 Shafi Goldwasser,Silvio Micali 和 Charles Rackoff 在 1985 年提交的开创性论文《The Knowledge Complexity of Interactive Proof-Systems》,三位作者也因此在 1993 年获得首届哥德尔奖。 论文中提出了零知识证明要满足三个条件:
交互式零知识证明相对容易构造,需要通过证明人和验证人之间一系列交互完成。一般为验证人提出一系列问题,证明人如果能都回答正确,则有较大概率确实知道论断。 例如,证明人 Alice 向验证人 Bob 证明两个看起来一样的图片有差异,并且自己能识别这个差异。Bob 将两个图片在 Alice 无法看到的情况下更换或保持顺序,再次让 Alice 识别是否顺序调整。如果 Alice 每次都能正确识别顺序是否变化,则 Bob 会以较大概率认可 Alice 的证明。此过程中,Bob 除了知道 Alice 确实能识别差异这个论断外,自己无法获知或推理出任何额外信息(包括该差异本身),也无法用 Alice 的证明(例如证明过程的录像)去向别人证明。注意这个过程中 Alice 如果提前猜测出 Bob 的更换顺序,则存在作假的可能性。
非交互式零知识证明(NIZK)则复杂的多。实际上,通用的非交互式完美或概率零知识证明(Proof)系统并不存在,但可以设计出计算安全的非交互式零知识论证(Argument)系统,具有广泛的应用价值。 Manuel Blum、Alfredo De Santis、Silvio Micali 和 Giuseppe Persiano 在 1991 年发表的论文《Noninteractive Zero-Knowledge》中提出了首个面向“二次非连续问题”的非交互的完美零知识证明(NIPZK)系统。 2012 年,Nir Bitansky、Ran Caneetti 等在论文《From extractable collision resistance to succinct non-interactive arguments of knowledge, and back again》中提出了实用的非交互零知识论证方案 zk-SNARKs,后来在 Z-cash 等项目中得到广泛应用。目前,进行非交互式零知识论证的主要思路为利用所证明论断创造一个难题(一般为 NP 完全问题如 SAT,某些情况下需要提前或第三方提供随机数作为参数)。如果证明人确实知道论断,即可在一定时间内解决该难题,否则很难解答难题。验证人可以通过验证答案来验证证明人是否知晓论断。
可验证随机函数(Verifiable Random Function,VRF)最早由 Silvio Micali(麻省理工学院)、Michael Rabiny(哈佛大学)、Salil Vadha(麻省理工学院)于 1999 年在论文《Verifiable Random Functions》中提出。 它讨论的是一类特殊的伪随机函数,其结果可以在某些场景下进行验证。一般可以通过签名和哈希操作来构建。 例如,Alice 拥有公钥 Pk 和对应私钥 Sk。Alice 宣称某可验证随机函数 F 和一个输入 x,并计算 y = F(Sk, x)。Bob 可以使用 Alice 公钥 Pk,对同样的 x 和 F 进行验证,证明其结果确实为 y。注意该过程中,因为 F 的随机性,任何人都无法预测 y 的值。 可见,VRF 提供了一种让大家都认可并且可以验证的随机序列,可以用于分布式系统中进行投票的场景。